之前360出的那个mongodb数据同步工具比较老,对于3.X版本的mongodb支持不太好。
阿里巴巴出了个 MongoShake , 目前可以支持到MongoDB4.X(我测试从mongodb3.2.16同步数据到mongodb4.0.4没问题)
官方地址:
中文介绍地址:
具体的介绍,可以参考上面第二个链接。 实际原理类似于 我们在mysql环境下常用的canal (MongoShake 通过订阅oplog, 然后给下游消费或者直接发送给下游mongodb实例)
MongoShake应用场景举例
1. MongoDB集群间数据的异步复制,免去业务双写开销。
2. MongoDB集群间数据的镜像备份(当前1.0开源版本支持受限)
3. 日志离线分析
4. 日志订阅
5. 数据路由。根据业务需求,结合日志订阅和过滤机制,可以获取关注的数据,达到数据路由的功能。
6. Cache同步。日志分析的结果,知道哪些Cache可以被淘汰,哪些Cache可以进行预加载,反向推动Cache的更新。
7. 基于日志的集群监控
MongoShake功能介绍
MongoShake从源库抓取oplog数据,然后发送到各个不同的tunnel通道。源库支持:ReplicaSet,Sharding,Mongod,目的库支持:Mongos,Mongod。现有通道类型有:
1. Direct:直接写入目的MongoDB
2. RPC:通过net/rpc方式连接
3. TCP:通过tcp方式连接
4. File:通过文件方式对接
5. Kafka:通过Kafka方式对接
6. Mock:用于测试,不写入tunnel,抛弃所有数据
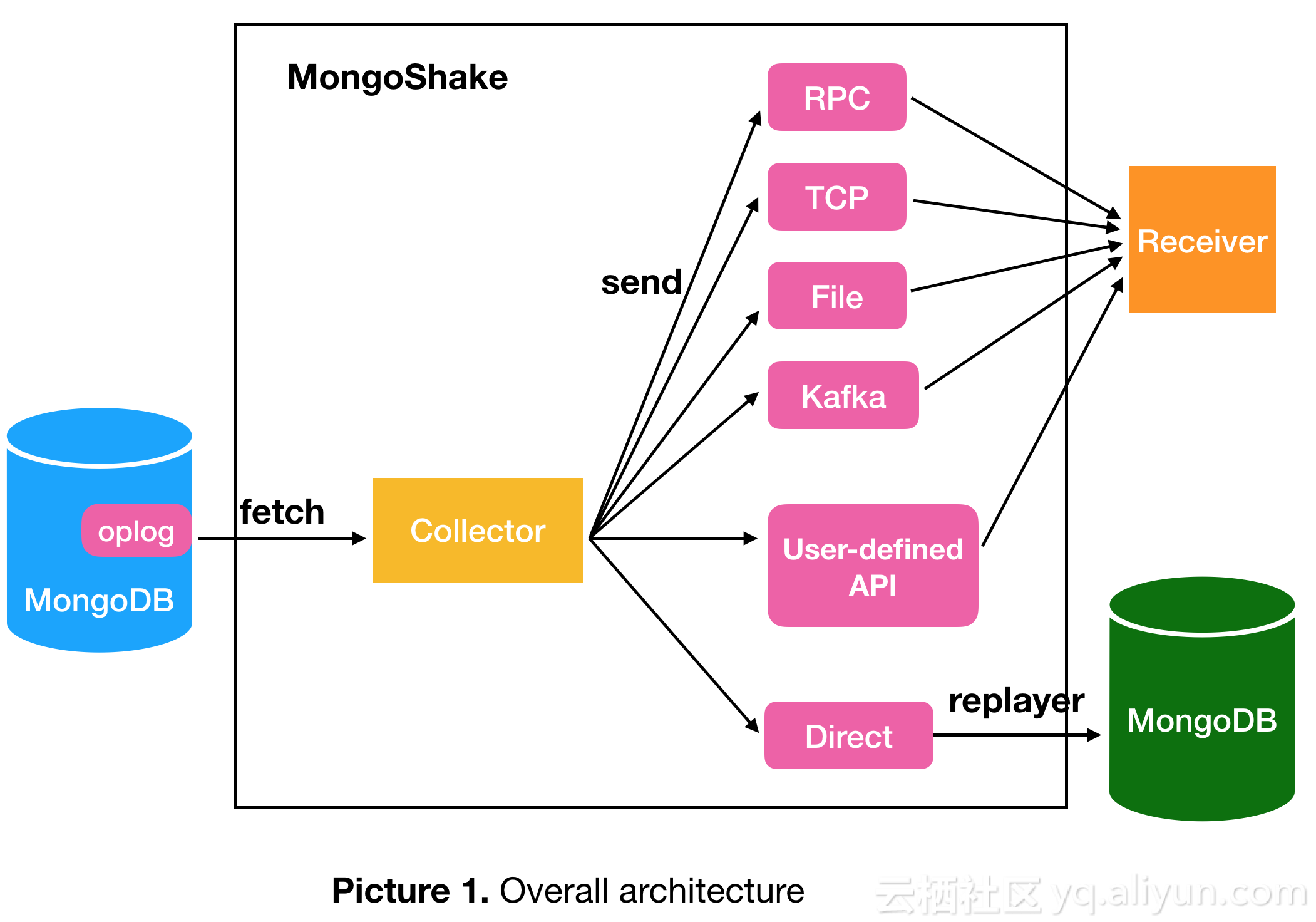
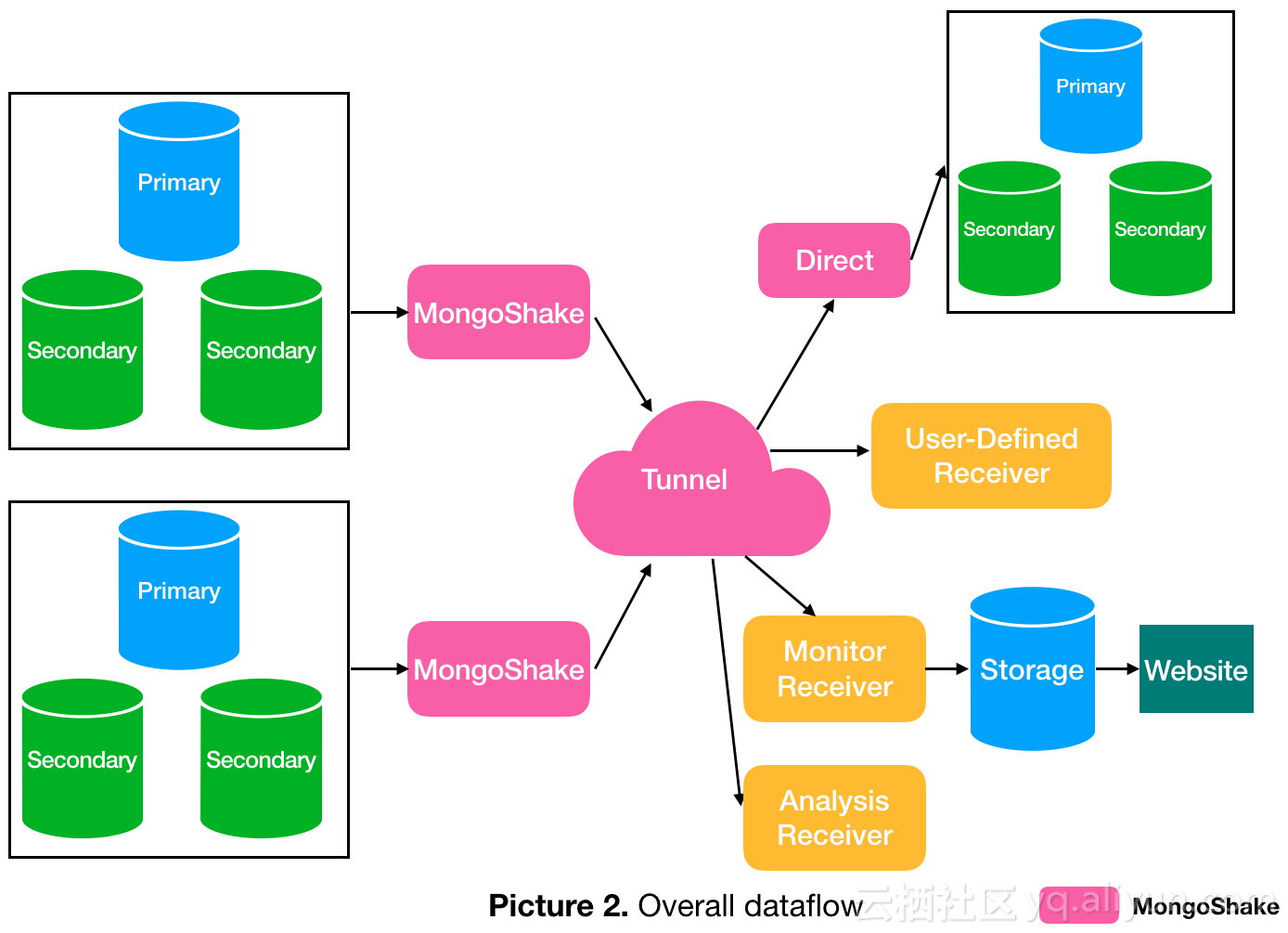
其它的介绍,可以参考上面的地址,这里就不大段贴了。
直接上实操吧:
环境: centos7
源库: mongodb 3.2.16
目的库: mongodb 4.0.4
mongo-shake的编译安装
yum install golang golang-bin golang-src # 我这里安装的是1.9.4的go包mkdir /home/gocode/export GOPATH=/home/gocode/echo 'export GOPATH=/home/gocode/' >> /root/.bashrcsource /root/.bashrcgit clone https://github.com/aliyun/mongo-shake.gitcd mongo-shake/src/vendorGOPATH=`pwd`/../..go get -u -v github.com/kardianos/govendor # 依赖到这个包,需要先安装下govendor/home/gocode/bin/govendor synccd ../../ && ./build.sh这样,就会在 bin目录下生成可执行的二进制文件
我这里编写的collector.conf 配置文件内容如下:
mongo_urls = mongodb://root:123456@192.168.2.4:27019 ## 如果是复制集环境,建议这里填从节点地址以减少主的压力collector.id = mongoshakecheckpoint.interval = 5000http_profile = 9100system_profile = 9200log_level = debuglog_file = collector.loglog_buffer = true# 配置同步的黑白名单filter.namespace.black = filter.namespace.white =oplog.gids = shard_key = autosyncer.reader.buffer_time = 1worker = 8worker.batch_queue_size = 64adaptive.batching_max_size = 16384fetcher.buffer_capacity = 256worker.oplog_compressor = nonetunnel = direct # 拿到的oplog 直接写到目标实例tunnel.address = mongodb://127.0.0.1:28017 # 目标库地址是 28017端口context.storage = databasecontext.address = ckpt_defaultcontext.start_position = 2000-01-01T00:00:01Zmaster_quorum = falsereplayer.dml_only = true ## 我这里只允许dml数据的同步,如果要允许ddl也传说到目标实例,需要把这个设置为false,具体参考官方的说明replayer.executor = 1replayer.executor.upsert = falsereplayer.executor.insert_on_dup_update = falsereplayer.conflict_write_to = nonereplayer.durable = true
启动方式:
./bin/collector -conf=conf/collector.conf
日志在 logs 目录下:
tailf logs/collector.log
在源实例上测试写入:
use testdb;for (i=1;i<=10000;i++) db.tb3.insert( {name:"student"+i, age:(i%120), address: "shanghai" } ); db.tb3.count() 然后,在目标节点执行验证操作:
use testdb;db.tb3.count()
可以看到,数据记录是一致的。 实际上测试下来,会有2秒左右的延迟。
其他走kafka,file ,rpc 等操作,没用到过,暂时不具备实验的条件。
如果只是单次的数据迁移,用dircet方式基本上就够了。 如果用在跨机房同步,一般建议走kafka的方式。